数据结构介绍:哈希,队列,栈,链表,树,二叉树,堆
哈希 Hash
Hash 就是 哈希。所有满足一个健(key)对应一个值(value)的形式的结构就是 hash,比如 HTTP 请求和 HTTP 响应的第二段。其实数组也是 hash,因为它也符合一个健一个值的定义。数组跟对象没有区别,数组就是对象。
哈希的应用
- 计数排序
- 基数排序
- 桶排序
计数排序
与之对应的比较排序,比较排序必须是两个数比较,它的过程中至少是遍历一次然后比较一次,最快的排序时间是 O(nlogn)。对应的排序快排,随机快排的时间复杂度就是 O(nlogn)。
原理:
- 把数组的值(假设数组项有 0)作为 hash 的 key,hash 的 value 记录每个值出现了多少次。
- 找出 hash 里面的最大值
- 从 0 到 hash 最大值作为 v 轮询 hash, hash[v] 个 数组的值 push 到 新的数组
- 返回新的数组
a <- { |
得到计数排序的复杂度是 O(n+max),比快排还快。
缺点
- 必须要有个 hash 作为计数排序的工具,
- 无法统计小数和负数进行排序
桶排序
多个桶,每个桶里面放多个数字,而且是一个范围内的数字。然后再对桶里面的数据进行排序。
比如:
hash = { |
数组的项差异比较大时。相对于计数排序,桶排序节约空间但是浪费时间。桶的个数随意。
基数排序
十进制的基数是十,二进制基数是二。根据基数来排序的就叫基数排序。先按照个位进桶,出桶;然后按照十位进桶,再出桶;然后按照百位进桶,然后出桶。以此内推。
在这里看基数排序的可视化原理过程 https://visualgo.net/bn/sorting
桶的个数是固定的 十个。能适用很大很大的数字。
| 排序 | 桶的个数 | 时间 |
|---|---|---|
| 计数排序 | 数组的长度多长桶就有多少个 | 进桶 n 出桶 max = n + max |
| 桶排序 | 开发根据数组项的范围来定义桶的个数 | 进桶常数级别 然后对桶里的值进行排序最快为 nlogn 然后出桶也是常数级别 = nlogn |
| 基数排序 | 按照十进制记录的桶个数即十个 | 个位进桶 n,出桶 n, 十位进桶 n,出桶 n, 百位进桶 n,出桶 n, 千位进桶 n,出桶 n … = 2倍位数的n |
队列 Queue
队列的概念是先进先出。可以用数组实现,数组的 push 进队,数组的 shift 出队。
const queue = [] |
现实生活中的排队场景就是队列。
在基数排序出桶的时候就是用的队列。
栈 Stack
概念是先进后出。也可以用数组实现的,数组的 push 进队,数组的 pop 出队。
const queue = [] |
盗梦空间就是一个栈的场景。
链表 Linked List
因为数组是连续的,数组的缺点,要删除某个值时,还要把这个值后面的项目往前移。链表也是 hash
a1 <- { |
改为 JavaScript 代码:
a1 = { |
如果要删除 a2, 直接把 a1 的 next 改为 a3 就可以了,也就是 a2 没有人引用了。
删除 a2 的话,代码就是直接执行 a1.next = a3 就可以了。
a1 = { |
链表的缺点,如果要取链表的第 n 项,需要 a.next.next….next,a点 n - 1 个 next 才能得到;但是数组就很方便,arr[n - 1] 就能取到数组里面的第 n 项。
比较而已,就是链表删除快,数组查询快。
最上层的 a 是 head,链表的表头,也是节点,然后其他的点叫节点。
树
有层级结构的地方就有树,比如 DOM 树。
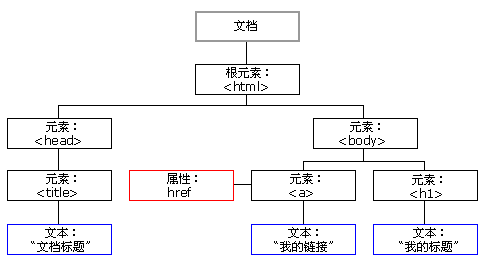
hash 分叉就是树,如果没有分叉就是链表。
节点下么有节点就是叶子节点,其他的叫普通节点,图上 DOM 树深度有 4 层,第 1/0 层 是 html,第 2 层是 head / body
二叉树
每次最多分 2 个叉,就是一个二叉树。
长满了叶子节点,满二叉树
左子树,右子树
二叉树的规律
| 层数 i | 那一层的最多有几个节点 | 所有层的节点 | 数组存树 |
|---|---|---|---|
| 0 | 1 (2^0) | 1 (2^1 - 1) | 数组的第 1 项存第 0 层 |
| 1 | 2 (2^1) | 3 (2^2 - 1) | 数组的 2 - 3 项目 存 第 1 层树 |
| 2 | 4 (2^2) | 7 (2^3 - 1) | 数组的 4 - 7 项 存 第 2 层 |
| 3 | 8 (2^3) | 15 (2^4 - 1) | 数组的 8 - 15 项 存 第 3 层 |
| 4 | 16 (2^4) | 31 (2^5 - 1) | 数组的 16 - 31 项 存 第 4 层 |
| 5 | 32 (2^5) | 63 (2^6 - 1) | 数组的 32 - 63 项 存 第 5 层 |
| 6 | 64 (2^6) | 127 (2^7 - 1) | 数组的 64 - 127 项 存 第 6 层 |
| 7 | 128 (2^7) | 255 (2^8 - 1) | 数组的 128 - 255 项 存 第 7 层 |
完全二叉树,除了最后一层外,若其余层都是满的,并且最后一层是满的,或者最后一层的右边连续没叶子节点。
通过二叉树的规律可以用数组实现完全二叉树,满二叉树。在上表中可以表示二叉树的各项:arr = [1, 2,3, 4,5,6,7, 8,9,10,11,12,13,14,15, 16]。这里就很好查询二叉树上某个节点的值了,比如获取第 3 层的第 1 个节点,也就是 arr[2^2 - 1] 得到 4。
其他二叉树或者树的形式就不适用这种方法了,因为树中有空节点。
堆排序
所有节点都满足子节点小于或者大于父节点,那这个树就是一个堆。
大顶堆是最大元素出现在根节点。arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆是最小元素出现在根节点。arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
原理
- 根据数组构建堆,将数组构建成一个无序的大顶堆(一般升序为大顶堆,降序为小顶堆)
- 将堆顶元素与末尾元素交换,使末尾元素最大。然后继续调整堆为大顶堆,再将堆顶元素与末尾元素交换,使末尾元素为第二大元素。如此反复进行交换、调整、交换……。完成排序。
const heapSort = arr => { |